include 지시자는 다른 JSP 파일을 현재 JSP 파일에 포함시킵니다. 이는 정적 포함 방식으로, 컴파일 시 포함됩니다.
<%@ include file="header.jsp" %>
코드 실습 1 - 주석을 사용해 보자
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%>
<!DOCTYPE html>
<html>
<head>
<title>JSP 주석 예제</title>
</head>
<body>
<!-- HTML 주석: 이것은 최종 HTML 페이지에 포함됩니다. -->
<%-- JSP 주석: 이것은 최종 HTML 페이지에 포함되지 않습니다. --%>
<%
// Java 주석: 한 줄짜리 주석
/* Java 주석:
여러 줄짜리 주석 */
%>
<h1>JSP 주석 예제</h1>
</body>
</html>
코드 실습 2 - JSP 지시자와 include 의 사용
header.jsp
header.jsp 파일에는 페이지의 헤더 부분을 포함합니다. 이 파일에는 <html>, <head>, <body> 태그를 열고, 공통으로 사용되는 스타일시트나 스크립트를 포함할 수 있습니다.
JSP 액션 태그(Action Tags) JSP 페이지에서 자바빈즈(Beans)를 사용하거나 다른 JSP 페이지를 포함시키는 등의 작업을 수행할 때 사용됩니다.
// 자바빈즈를 생성하거나 찾을 때 사용합니다.
<jsp:useBean id="myBean" class="com.example.MyBean" scope="session" />
// 자바빈즈의 속성 값을 설정할 때 사용합니다.
<jsp:setProperty name="myBean" property="username" value="JohnDoe" />
// 자바빈즈의 속성 값을 가져올 때 사용합니다.
<p>Username: <jsp:getProperty name="myBean" property="username" /></p>
// 다른 JSP 페이지를 포함시킬 때 사용합니다.
<jsp:include page="header.jsp" />
// 다른 JSP 페이지로 요청을 포워드할 때 사용합니다.
<jsp:forward page="nextPage.jsp" />
... 등
💡 자바빈즈(JavaBeans)란?
재사용 가능한 객체: 자바빈즈는 재사용 가능하도록 설계된 Java 객체입니다. 특정 규약이 적용된 객체: 자바빈즈는 캡슐화, 기본 생성자, 직렬화 등의 규약을 따릅니다. 캡슐화(Encapsulation): 필드는 private으로 선언하고, 접근자 메서드(getter)와 설정자 메서드(setter)를 통해 접근합니다. 기본 생성자(Default Constructor): 자바빈즈 클래스는 기본 생성자를 반드시 가져야 합니다. 직렬화(Serialization): 자바빈즈는 Serializable 인터페이스를 구현하여 직렬화할 수 있습니다. 데이터 저장, 연산 및 전송: 자바빈즈는 애플리케이션에서 데이터를 저장하고, 연산을 수행하며, 다른 컴포넌트나 시스템으로 데이터를 전송하는 데 도움을 줍니다.
정리 - 동일한 클래스를 여러 곳에서 인스턴스화 해서 사용가능하며 스코프(scope) 내에서 재사용될 수 있습니다. 세션 스코프(scope)에서 생성된 자바빈즈 객체는 세션 내내 동일한 객체로 유지될 수 있습니다.
자바빈즈와 스코프
page: 현재 페이지에서만 사용 가능 (기본값) request: 하나의 요청 동안 사용 가능 session: 세션 동안 사용 가능 application: 애플리케이션 전체에서 사용 가능
코드 실습 1 - 인사말 생성기
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
</head>
<body>
<h1>인사말 생성기</h1>
<!-- 절대 경로 -->
<!-- 상대 경로 -->
<form action="greet.jsp" method="POST">
<label for="name">당신에 이름을 입력하세요: </label>
<input type="text" id="name" name="name" >
<button type="submit">서버로 제출</button>
</form>
</body>
</html>
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<!-- JSP 페이지의 설정을 정의하는 지시자 -->
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
</head>
<body>
<h1>인사말을 완성 하였습니다.</h1>
<%
// 자바 실행 코드
// request 객체에서 값 추출
String name = request.getParameter("name");
if(name == null || name.trim().isEmpty()) {
out.println("<p> 앗! 당신에 이름을 먼저 입력해주세요 </p>");
} else {
out.print("<p>반가워, " + name + "! 나의 JSP Site 잘 왔어 환영~~");
}
%>
<!-- 다시 이전 페이지로( 특정 페이지로 이동) -->
<a href="greet_from_page.html">Back</a>
</body>
</html>
1. JSP의 정의와 역할을 이해한다. 2. JSP의 장점과 특징을 파악한다. 3. JSP와 관련된 기본 용어를 익힌다.
1. JSP란 뭘까?
Java Server Pages (JSP)는 동적인 웹 콘텐츠를 생성하기 위한 서버 측 기술이다. JSP는 HTML 페이지 내에 Java 코드를 포함시켜 웹 서버에서 실행된 후, 클라이언트에 HTML을 전송하는 방식으로 동작한다. 좀 더 자세히 말하자면 JSP(Java Server Pages)는 자바 서버 페이지의 약자로, 웹 애플리케이션 개발을 위한서버 사이드 기술(Server-Side Rendering)입니다. JSP는 HTML, CSS, JavaScript 등의 클라이언트 사이드 언어와 함께 사용되어 동적인 웹 페이지를 생성하는 데 사용됩니다. 자바 코드를 HTML 코드에 삽입하여 웹 서버에서 실행할 수 있게 해주며, 그 결과는 클라이언트의 웹 브라우저로 전송됩니다.
SSR은 Server-Side Rendering(서버 측 렌더링)의 약어입니다. SSR은 클라이언트에게 웹 페이지를 제공하기 전에 서버에서 웹 페이지를 렌더링하여 HTML을 생성하는 웹 개발 방법론입니다. 이 방법론은 클라이언트에게 정적인 HTML을 먼저 제공하고, 클라이언트 측에서 JavaScript를 사용하여 동적인 콘텐츠를 추가하는 방식인 Client-Side Rendering(CSR)과 대비됩니다.
2. Servlet vs JSP
JSP 역할
웹 애플리케이션에서 사용자 요청을 처리하고, 동적으로 생성된 HTML을 클라이언트에게 반환한다. 프론트엔드와 백엔드의 중간 역할을 하며, HTML과 같은 프론트엔드 코드와 Java와 같은 백엔드 코드를 혼합하여 사용할 수 있다.
JSP의 기본 동작 원리
클라이언트 요청: 클라이언트(웹 브라우저)가 JSP 페이지에 접근한다.
서버 처리: 웹 서버(아파치 톰캣)가 JSP 페이지를 찾아 Java 서블릿으로 변환한 후 컴파일하여 실행한다.
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>JSP Example</title>
</head>
<body>
<h1>JSP Example</h1>
<hr>
<%-- JSP 디렉티브 : 페이지 속성 설정 --%>
<%@ page import="java.util.Date" %>
<%@ page import="java.text.SimpleDateFormat" %>
<%-- JSP 스크립트릿 : Java 코드 영역 --%>
<%
// 현재 날짜와 시간을 가져오기
Date now = new Date();
// 날짜 포맷 지정
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String formattedDate = sdf.format(now);
%>
<%-- HTML과 함께 JSP 표현식 사용하여 날짜 출력 --%>
<p>현재 시간: <%= formattedDate %></p>
<%-- JSP 선언문 : 변수 선언 --%>
<%!
int number = 10;
String message = "Hello, JSP!";
%>
<%-- HTML과 함께 JSP 표현식 사용하여 변수 출력 --%>
<p>숫자: <%= number %></p>
<p>메시지: <%= message %></p>
<%-- JSP 주석 : HTML 주석 --%>
<!-- 이 부분은 HTML 주석입니다. JSP에서는 이렇게 사용할 수 있습니다. -->
<%-- JSP 액션 태그 : Java 코드 실행 및 제어 --%>
<%-- if-else 구문 --%>
<% if (number > 5) { %>
<p>숫자가 5보다 큽니다.</p>
<% } else { %>
<p>숫자가 5보다 작거나 같습니다.</p>
<% } %>
<%-- JSP 액션 태그 : include 지시자를 사용한 다른 JSP 파일 포함 --%>
<%-- <%@ include file="included.jsp" %> -->
<%-- JSP 표현언어(EL) : 변수 값 출력 --%>
<p>EL 표현식을 사용한 숫자: ${10}</p>
<p>EL 표현식을 사용한 메시지: ${"Hello, JSP!"}</p>
</body>
</html>
JSP 처리 과정
웹 브라우저에 JSP 페이지에 해당하는 URL을 입력하면, 톰캣 서버는 다음과 같은 과정을 거쳐 JSP 페이지를 실행한다.
JSP를 실행한다는 말은 곧 JSP 페이지를 컴파일한 결과인 서블릿 클래스를 실행한다는 의미가 된다.
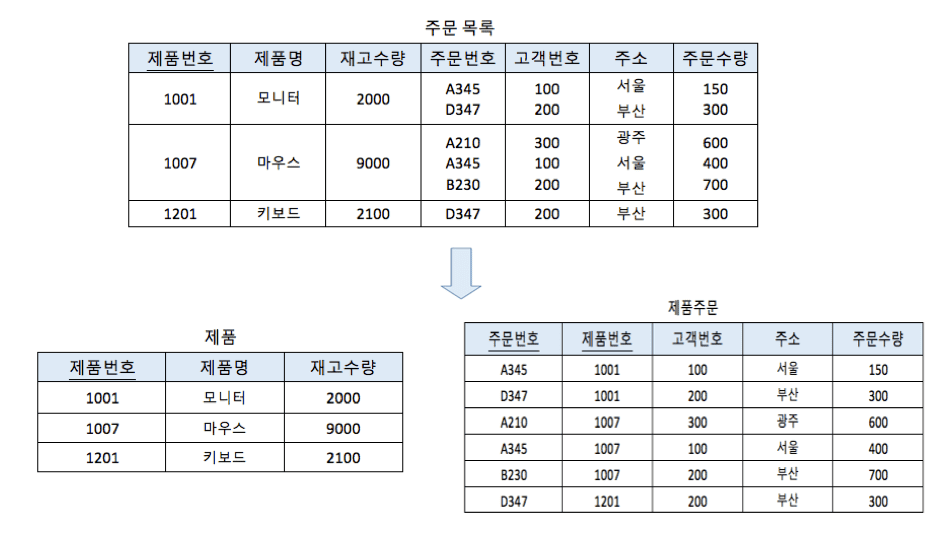
단순화 : 현실세계를 '정해진 표기법'으로 단순하고 쉽게 표현, 핵심에 집중하고, 불필요한 것은 제거
명확화 : 불문명(애매모호한 것)을 제거하고, '정확하게' 현살을 기술
목적
단순히 데이터베이스, 시스템 만을 구축하기 위한 것이 아닌 업무설명, 분석, 형상화 목적도 있음
분석된 모델로 실제 데이터베이스를 생성하며 개발 및 데이터 관리에도 사용함
데이터 모델링 유의점 및 3가지 관점 그리고 중요 3요소
유의점
중복(Duplication) : 같은 데이터가 엔터티에 중복 저장되면 안된다.
비유연성(Inflexibility) : 애플리케이션의 '사소한 변경'에도 데이터 모델이 수시로 변경하면 안된다.
-> 데이터 모델과 프로세스 분리해서 유연성을 높여야 한다
비일관성(Incosistency) : 중복이 없는 경우에도 비일관성 발생 가능성 있음
-> 데이터 간의 연관 관계에 대해 명확하게 정의
관점
데이터 관점(What, Data) : 어떤 데이터들이 업무와 얽혀있는지
프로세스 관점(How, Process) : 업무가 실제로 처리하고 있는 일이 무엇인지
데이터와 프로세스의 상관 관점(Data vs Process, Intercation) : 프로세스 흐름에 따라 데이터가 어떤 영향을 받는지
중요요소
Things : 대상(Entity)
Attribute : 속성
Relationships : 관계
모델링의 3가지 단계
개념적 모델링 : '전사적'으로 수행, 업무 중심적이고 포괄적인 수준의 모델링(추상화 레벨 가장 높음)
논리적 모델링 : Key, 속성, 관계들을 표현하는 단계 -> 정규화 활동이 이루어지는 단계 : 논리 데이터모델을 대상으로 정규화하는 것
물리적 데이터 모델링 : 실제 DB를 구현할 수 있도록 성능, 가용성등 물리적 요소 고려하는 단계
데이터 스키마 단계에 따른 독립성
스키마란?
테이블이 어떠한 구성으로 되어있는지, 어떤 정보를 가지고 있는지에 대한 기본적인 테이블의 구조를 정의한 것
데이터 스키마의 구조
출처 : DBGUIDE.NET
사용자
외부 스키마 : 각(여러) 사용자가 보는 스키마 정의 및 표현
개념 스키마 : 모든(여러X) 사용자가 보는 데이터 정의 및 표현 & 관계를 정의하는 단계
내부 스키마 : 물리적인 저장 구조를 나타내는 단계 -> 저장 구조, 칼럼, 인덱스 정의
데이터 베이스
논리적 독립성 : 개념스키마가 변경 되어도 외부 스키마는 영향 X [외부] - [개념]
물리적 독립성 : 내부스키마가 변경 되어도 개념/외부 스키마는 영향 X [외부, 개념] - [내부]
ERD 작성 순서
엔터티 도출
엔터티 배치
엔터티 관계 설정
관계명 기입
관계 참여도 기입
관계 필수/선택 여부 기입
Entity는 네 부분의 모서리가 둥근 형채인 Soft-box로 표현함
Entity 이름은 Box 내부 상단에 표시
Attribute 중 필수로 값을 입력하며 식별자인 속성은 #(Mandatory)를 표시
Attribute 중 필수로 값을 입력하여야 하는 속성은 *(Mandatory)를 표시
Attribute 중 선택적인 입력을 입력하여야 하는 속성은 º(Optional)를 표시
엔터티란? 엔터티의 특징
업무에 쓰이는 데이터들을 용도별로 분류한 데이터의 그룹 = 엔터티
엔터티의 특징
업무에서 쓰이는 정보여야 함
식별자가 있어야 함
2개 이상의 인스턴스를 가져야 함
반드시 속성을 가져야 함 -> 이 때 하나의 인스턴스는 2개 이상의 속성을 가짐 -> 즉 하나의 엔터티는 2개 이상의 속성을 가짐
다른 엔터티와 1개 이상의 관계
엔터티 분류 방법과 그에 따른 종류
유형, 무형에 따른 분류
유형 엔터티 : 모델링 대상이 물리적인 형태가 존재 (ex) 상품, 회원
개념 엔터티 : 모델링 대상이 형태 없음 (ex) 부서, 학과
사건 엔터티 : 모델링 대상이 행위로 인해 발생하는 것 (ex) 주문, 이벤트 응모
발생 시점에 따른 분류
기본 엔터티 : 모델링 대상이 업무에 대해 원래 존재하는 요소 -> 독립적, 자식 엔터티 가질 수 있음 (ex) 상품, 회원, 부서
중심 엔터티 : 모델링 대상의 업무 과정 중 하나, 기본 엔터티로부터 파생, 행위 엔터티 생성 (ex) 주문, 매출, 계약
행위 엔터티 : 2개 이상의 엔터티로부터 파생 (ex) 주문 내역, 이벤트 응모 이력 등
엔터티 명명 주의점
업무에서 실제 쓰이는 용어 사용
한글 약어 사용 X, 영문 대문자로 표시
단수 명사로 표현, 띄어쓰기 X
의미상 중복 X (주문, 결제 엔터티는 중복 가능)
명확하게 표현할 것
속성? 속성의 특징
엔터티의 특징을 나타내는 최소의 데이터 단위
속성의 특징
더 이상 쪼개지지 않는 레벨
업무에서 필요로 하는 항목
엔터티를 설명, 인스턴스를 설명
하나의 속성은 하나의 속성값만 가짐 -> 여러 개 가지면 1차 정규화
일반 속성은 정해진 주식별자에 함수적 종속성 가져야한다. -> 완전 함수적 종속이 아닌 부분 종속이면 2차 정규화 해준다. ex) PK가 2개의 속성으로 이루어져있는데 {속성1, 속성2} 에서 속성 2에만 종속성 가지면 2차 정규화로 엔터티 추가 생성해서 각 엔터티마다 완전 함수적 종속 충족시켜줌
속성의 특성에 따른 분류
일반적인 특성에 따른 분류
기본 속성 : 업무 프로세스(기본 틀) 분석했더니 바로 정의 가능한 속성
설계 속성 - 인스턴스에 유니크함을 부여하는 속성(PK의 토대) : 업무엔 없으나, 모델링 하다보니 고유함 보전하기 위해 필요해져서 만들어짐 ex) 학번, 사번 등등
파생 속성 -> 성능, 편의 위해 새로 만든 엔터티의 속성 : 데이터를 조회할 때 빠른 성능 낼 수 있도록 원래 속성값을 계산하여 저장할 수 있도록 하는 속성 ex) 평균, 재고 등
구성 방식(각 속성 및 엔터티와의 관계)에 따른 분류
PK 속성 : 인스턴스의 유니크함을 부여하는 속성, 일반 속성들의 종속성을 가진 키 (기본키, 주식별자 키) #으로 표현 (ex) 학번, 사번
FK 속성 : 다른 엔터티에서 가져온 속성(외래키), 다른 엔터티와의 관계를 맺게 해줌 -> 주식별자에 있는 속성이 FK가 될 수 있음 (ex) #사원번호(FK)
일반 속성 : PK, FK를 제외한 나머지 속성
속성의 분해 가능 여부에 따른 분류
단일 속성 : 속성이 하나의 의미로 구성
복합 속성 : 여러개의 의미로 구성(주소 = 시 + 구 + 동)
다중 값 속성 : 속성이 여러 개 값 가짐 -> 1차 정규화 or 별도 엔터티 생성
속성이 만들어 낸 데이터 모델의 개념
도메인 : 속성이 가질 수 있는 속성 값의 범위
용어 사전 : 속성의 이름을 정확, 직관적으로 부여하기 위한 용어사전
시스템 카탈로그 : 시스템 자체에 관련있는 데이터를 가진 DB : 시스템 테이블로 구성 & SQL로 조회 가능 : 여기에 저장된 데이터 = 메타 데이터, SELECT만 가능 INSERT, UPDATE 등등 불가능
관계란? 관계의 종류
엔터티와 엔터티 사이에 속성끼리의 연결에 의해 만들어지는 상관 관계
종류
존재 관계 : 모델링 된 엔터티들이 존재로서 관계를 가짐
행위 관계 : 모델링 된 엔터티들이 행위에 의해 관계를 가짐
UML의 클래스 다이어그램에 의해 나뉘는 종류
연관 관계 : 필수적 관계(존재적 관계, 식별자 관계) - 항상 서로 이용(실선) : 멤버 변수로 선언
의존 관계 : 선택적 관계(비식별자 관계) - 상대 클래스 행위에 따라 이용(점선) : 행위 코드 오퍼레이션에서 파라미터로 사용
관계 표기 방법(ERD)에 따른 특성 분류
관계명 : 관계 이름은 시작 엔터티 - 능동적 / 끝 엔터티 - 수동적 '동사' 사용
관계 차수 : 각 엔터티 끼리의 관계에 참여하는 '속성의 수', 1:1, 1:M, M:N 형식으로 구분
관계 선택 사양 : 필수적 관계(엔터티끼리 항상 관계), 선택적 관계(행위에 의해 관계 여부가 성립) ex) 한 수업 엔터티에 참여 엔터티, 과제 엔터티가 있으면 참여는 수업이 있을 때 마다 항상 관계가 성립되어서 조회가 되지만, 과제는 과제가 있는 날에만 관계를 맺고 조회가 되기 때문에 이러한 것을 구분함
관계 체크 사항(두 엔터티 사이 관계 정의 시 유의할 사항)
두 엔터티 사이 관심있는 연관 규칙이 존재하는가?
두 엔터티 사이 정보의 조합이 발생하는가?
업무 기술 시, 장표의 관계 연결을 가능하게 하는 동사가 있는가?
업무 기술 시, 장표의 관계 연결을 가능하게 하는 규칙이 서술되어 있는가?
식별자란? 주 식별자의 특성
각각의 인스턴스를 구분 가능하게 만들어주는 대표 속성을 뜻한다.
주 식별자란? 주 식별자의 특성 # 으로 표현
주 식별자는 PK(Primary Key)에 해당하는 속성 - PK는 여러개 존재할 수 있음
유일성 : 해당 속성이 인스턴스를 유일하게 식별할 수 있는 성질을 가졌는지
최소성 : 최소한의 속성들로만 유일성을 보장하게 하는지
불변성 : 속성값이 변하지 않아야함
존재성 : 속성값은 NULL이 될 수 없음 -> ex) 유일성과 최소성을 만족하는 속성은 보조키로서 존재할 수 있다. -> 즉 특정 특성을 만족함에 따라 속성은 특정 키로서 존재가능
식별자의 특성과 특정 여부에 따른 분류
대표성 여부
주 식별자(PK) - # 으로 표현 : 유일성, 최소성, 불변성, 존재성을 모두 만족하는 식별자 -> PK는여러 속성이 존재할 수 있으나, 여러속성이 존재 할 경우 나머지 일반 속성들이 해당 PK들 속성들에 대해 함수적 종속성을 띄어야 함 -> 그렇지 않으면 2차 정규화하여 부분 종속에 해당하는 속성들만 따로 추가 엔터티를 생성한다.
주 식별자 도출 기준
해당 업무에서 자주 이용되는 속성
명칭, 내역 등의 이름은 피함
속성 수를 최대한 적게 구성
자주 변하지 않는 값
보조 식별자 : 인스턴스 식별은 가능하다 엔터티를 대표하는 식별자는 아님 -> 즉 다른 엔터티와의 참조 관계로 연결되지 않는다. ex) 회원 엔터티에서 # 회원번호 * 회원명 * 아이디 에서 아이디는 다른 인스턴스랑 중복 될 수 없기 때문에 해당 엔터티에서 인스턴스를 구분짓게 할 수 있는 식별자이나 이것이 엔터티를 대표하지는 못함
스스로 생성되었는가에 대한 여부
내부 식별자 : 다른 엔터티 참조 없이 해당 엔터티 내부에서 스스로 생성된 식별자
외부 식별자 : 다른 엔터티에서 온 식별자 - 다른 엔터티와 연결고리 역할 -> 만약 부모 엔터티의 FK를 받아서 이를 주식별자로 사용하면 -> 해당 자식 엔터티의 PK는 SQL 조인에서 반드시 사용되고 WHERE 절에서 사용 가능성이 높음
단일 속성인지에 대한 여부(주식별자 구성이 여러 속성인가)
단일 식별자 : 주 식별자가 1개의 속성으로 구성
복합 식별자 : 주 식별자가 2개 이상의 속성으로 구성 : 주 식별자가 2개 이상이면 해당 속성들의 우선순위를 잘 매겨서 잘 복합시킨 후 일반 속성들에게 종속시켜야 주 식별자로서 기능을 다하게 된다.
대체되었는지 기존에 있는지에 대한 분류
원조(본질) 식별자 : 업무에 의해 만들어지는 식별자, 가공되지 않은 원래 식별자
인조(대리) 식별자 : 인위적으로 만들어지는 식별자, 주 식별자가 복잡할 때 이를 통합 ex) 주문 번호 - 대표적 인조, 대리 식별자 기존 : 사번 + 주문일자 + 순번을 주 식별자로 두고 주문을 처리하다가 이를 '주문번호' 라는 단일 속성의 주 식별자로 만들면 이게 인조, 대리 식별자가 됨
식별자관계와 비식별자 관계
식별자 관계
트랜잭션에 의한 관계 - 동시에 커밋, 롤백 - 하나의 커밋 단위로 엔터티들이 묶임
: 부모 엔터티의 식별자 속성이 자식 엔터티의 주 식별자가 되는 관계
강한 연결 관계
실선(항시 연결)
부모 - 자식 관계가 항시 유지
SQL문의 조인을 최소화 해줌
비식별자 관계
: 부모 엔터티의 식별자 속성이 자식 엔터티의 일반 속성이 되는 관계
약한 연결관계
점선(선택적 연결)
부모 - 자식 관계가 유지 안 될 수있음 -> 일반 속성 값은 Null이 들어갈 수 있기 때문에 부모 엔터티의 식별자 속성에 값이 없을 때 자식 엔터티의 속성 값(인스턴스)이 생성 가능하다.
데이터 모델과 SQL
성능 데이터 모델링 개요
1. 성능 데이터 모델링의 정의
성능 저하의 원인 중 하나는 데이터 모델링의 근본적인 디자인이 잘못되어 있는 경우도 많다.
따라서 성능 데이터 모델링을 통해 성능향상을 도모해야한다.
성능 데이터 모델링이란?
데이터베이스 성능향상을 목적으로 설계단계의 데이터모델링 때부터 성능과 관련된 사항이 모델링에 반영될 수 있도록 하는 것
2. 성능 데이터 모델링 수행시점
사전에 성능 모델링을 할 수록 성능 향상을 위한 비용은 적게 든다.
분석/설계 단계에서 성능을 고려해 데이터 모델링을 수행할 경우 재업무 비용을 최소화할 수 있다.
따라서 분석/설계 단계에서 처리성능을 향상시킬 방법을 고려해야한다.
3. 성능 데이터 모델링 고려사항
성능 데이터 모델링 프로세스
정규화
DB 용량 산정
트랜잭션의 유형 파악 -> 테이블 수직 분할 할 때(반정규화)
용량과 트랜잭션의 유형에 따라 반정규화
이력모델 조정, PK/FK 조정, 슈퍼타입/서브타입 조정
성능관점에서 데이터 모델을 검증
정규화
정규화란?
엔터티를 작은 단위로 분리하는 과정
-> 큰 엔터티를 작은 엔터티들로 분리하고 관계 맺음
: 논리 데이터 모델에서 행하는 과정이다. (개념 모델링 X, 물리 모델링 X)
정규화의 특징 및 하는 이유와 개념
데이터의 무결성을 위해 수행
최소한의 데이터만을 하나의 엔터티에 넣는 과정, 데이터 분해 과정
데이터 일관성 확보
데이터 독립성 확보 - > 데이터 중복 제거
데이터 유연성 확보 -> 필요 데이터들의 분할로 인해 유연하게 접근 가능
입력, 수정, 삭제 성능은 일반적으로 향상 -> 조회 성능이 저하 될 수 있음
정규화의 단점
엔터티 갯수 증가 - 이로 인한 관계가 증가함
데이터 조회 시 여러번의 조인이 요구됨
조회 성능의 저하
식별자, 비식별자와 헷갈리지 말 것 -> 식별자 = join 최소화
정규화의 종류
각 정규화를 통해 이루어지는 행위가 있는데 이 행위를 만족하는 엔터티 구조는
제 1 정규형 릴레이션, 제 2 정규형 릴레이션, 제 3 정규형 릴레이션 이라고 칭한다.
제 1 정규화
테이블 칼럼들이 원자성(특성의 중복을 방지) 갖게 하기 위해 엔터티 분해
-> 하나의 인스턴스가 비슷한 속성을 여러개 가지지 않게 하기 위해 분리하는 것
제 2 정규화
'부분 종속'이 아닌 '완전 종속'을 가져야 한다.
이 때 만약 '부분 종속'을 가지는 일반 속성이 있다면 해당 속성과 해당 속성의 결정자인 부분 종속을 이루고 있는 주 식별자의 속성을 따로 떼어내 추가적인 엔터티를 만들어 제 2정규형을 만족하는 릴레이션을 구축하는 것
또는 주 식별자의 속성이 아닌 일반 속성 끼리 종속 관계를 맺어도 이에 대해 해당 일반 속성이 새로운 엔터티에서 제 2 정규성을 만족하도록 엔터티를 추가적으로 만들어준다.
제 3 정규화
정규화된 엔터티의 일반 속성들은 주 식별자에만 함수적 종속을 가져야한다.
그런데 만약 주 식별자의 속성들끼리 종속 관계를 가지고 그 이후에 또 일반 속성에 대해 결정자가 되던지 일반 속성끼리 종속성을 가지는데 이 때의 결정자가 주 식별자 속성에 종속되어 있는 등
A -> B, B -> C와 같은 '이행적 종속'을 이루는 TABLE(엔터티)일 때 이러한 '이행적 종속'을 깨도록 추가적인 엔터티를 만들고 관계를 형성해주는 것이 제 3 정규화이다.
BCNF 정규화
모든 결정자가 후보키가 되도록 테이블을 분해하는 것
-> 후보키 : 식별자의 '유일성', '최소성'을 만족하는 속성 집합(or 단일 속성)
제 4 정규화
여러 컬럼이 하나의 칼럼 종속시킬 때 분해해서 '다중값 종속성' 제거
제 5 정규화
조인에 의해 새로운 종속성이 발생 이를 막기 위해 엔터티 재 분해
반 정규화
반정규화란? 특징과 하는 이유?
정규화된 데이터 모델(엔터티, 속성, 관계)에 대해 '성능 향상', '개발, 운영의 단순화'를 위해 데이터를 중복, 통합, 분리하는 기법
정규화 시 엔터티 갯수 증가, 관계 증가 -> 여러 조인을 요구
이러한 경우 디스크 I/O 양이 많아져 성능이 저하되거나 경로가 멀어서 '조인'으로 인한 성능 저하가 예상
비 정규화 = 정규화를 하지 않음
반 정규화 = 위 내용을 하는 것
반 정규화의 특징
조회(SELECT) 속도 향상
데이터 모델의 유연성은 저하 -> 입력/수정/삭제 성능 저하
반정규화 하는 경우
정규화를 통해 엔터티, 관계 수가 많아져서 조회 시 '조인'으로 인한 성능 저하가 예상될 때
컬럼을 계산하고, 읽을 때 FK라서 여러 조인을 또 불러와서 성능이 저하 될 때 -> 즉 조인으로 인한 I/O 양이 너무 많아져서 처리 성능이 저하 될 때 -> 중복성을 증가시켜 조회 성능을 향상시킨다.
반정규화 안하면 발생하는 문제
성능 저하된 DB 생성
구축, 시험 단계에서 수정에 따른 노력 비용 발생
테이블을 가지고 반정규화 방법(병합, 분할, 추가)
테이블 병합
1:1 관계 테이블 병합
1:M 관계 테이블 병합
슈퍼 서브 타입 테이블 병합 -> 공통 속성과 개별 속성을 별도로 관리하는 설계 타입
테이블 분할
테이블 수직 분할(속성 분할) : 트랜잭션 처리 유형 파악이 필요 -> 반정규화에서 테이블 수직 분할 할 때 필요 -> 테이블 속성 개수 많을 때, 조회 성능 향상을 위해 -> 자주 쓰이는 속성을 수직 분할 -> 이후 1:1 관계를 이루게 된다.
테이블 수평 분할(인스턴스 분할, 파티셔닝) : 물리적으로 데이터 분리
테이블 추가
중복 테이블 추가 : 동일한 테이블 구조 중복, 원격 조인 제거
통계 테이블 추가 : SUM, AVG등 전용 테이블 추가
이력 테이블 추가 : 마스터 테이블의 레코드를 긁어서 테이블 추가 생성
부분 테이블 추가 : 이용 빈도 높은 컬럼을 복사하여 별도 테이블 생성, 물리적 디스크 I/O 줄이기 위해
컬럼을 통해 반정규화 하는 방법
중복 컬럼 추가 -> 중복 추가는 다 JOIN 감소 시키기 위해(중복 테이블 추가) : 조인 감소를 위해 중복 칼럼 추가 ex) 최근 상품 가격
파생 컬럼 추가 -> 파생 속성이 이것을 뜻함 -> 부하 줄이기 : 미리 값을 계싼하여 컬럼에 보관
이력 테이블 컬럼 추가 : 대량의 이력 데이터를 처리할 때 기능성 컬럼(최근값 여부, 시작&종료일 등)을 추가
PK에 의한 컬럼 추가 : 여러 컬럼으로 이루어진 PK를 가진 테이블을 조인할 경우 단순성을 위해서 인공키를 PK로 지정하고 활용
응용 시스템 오작동을 위한 이전 데이터 보관 컬럼 추가 : 이전 데이터를 임시적으로 중복하여 보관
관계를 통해 반정규화 하는 방법
중복 관계 추가 방법
여러 경로를 거쳐 조인 할 수 있지만, 성능 저하를 예방하기 위해 추가적인 관계를 맺음 -> 중복 관계 추가는 데이터 무결성을 깨뜨릴 위험성이 없음 -> 이에 무결성을 지키면서 처리 성능을 향상 시킬 수 있음
관계와 조인
관계란?
부모 엔터티의 식별자를 자식에 상속하고, 상속된 속성을 매핑키(조인키)로 활용
관계의 분류
존재 관계
행위 관계
조인이란?
데이터 중복을 피하기 위해 테이블은 정규화에 의해 분리
-> 이렇게 분리된 테이블을 동시에 출력하거나 관계가 있는 테이블 참조 위해서는 테이블 연결
-> 이 때 이러한 연결 과정을 조인이라 칭한다.
계층형 데이터 모델
하나의 엔터티 내에서 인스턴스 끼리 계층 구조를 가지는 경우
-> 계층 구조를 갖는 인스턴스끼리 연결하는 조인을 셀프조인이라 한다.
(같은 테이블 내에서 여러 번 조인 되는 것)
상호배타적 관계
하나의 부모가 2개의 자식 엔터티를 가질 때 행위 조건에 따라 두 자식 중 하나의 자식만 관계를 가질 수 있는 것을 상호배타적 관계라 칭한다.
트랜잭션이란?
트랜잭션의 특징
하나의 연속적인 업무 단위를 뜻함
트랜잭션에 묶인 엔터티들은 '필수적 관계'를 가짐
하나의 트랜잭션에 속한 동작들은 모두 성공하거나, 모두 취소(UNDO)되어야 한다. -> 트랜잭션의 '원자성'
-- 데이터베이스에서 데이터 유형에 대한 형변환을 할 수 있는 방법은 두 가지가 있다. -- 명시적 형변환 : 변환 함수를 사용하여 데이터 유형을 명시적으로 나타냄 -- 암시적 형변환 : 데이터베이스가 내부적으로 알아서 데이터 유형을 변환함 -- 예를 들어 조건절에서 VARCHAR 유형의 BIRTHDAY 컬럼을 숫자와 비교할 경우 -- 데이터베이스는 오류를 뱉지 않고 내부적으로 BIRRTHDAY 컬럼을 NUMBER형으로 변환하게 된다.
2. 명시적 형변환에 쓰이는 함수
-- SQL SERVER의 경우 CONVERT나 CAST 함수를 사용할 수 있다.
ㄱ. TO_NUMBER(문자열)
-- 문자열을 숫자형으로 변환해주는 함수
SELECT TO_NUMBER('1234') FROM DUAL;
SELECT TO_NUMBER('ABC') FROM DUAL; -- 오류발생
ㄴ. TO_CHAR(수 OR 날짜, [포맷]) *[]은 옵션
-- 수나 날짜형의 데이터를 포맷 형식의 문자형으로 변환해주는 함수
SELECT TO_CHAR(1234) FROM DUAL;
SELECT TO_CHAR(SYSDATE, 'YYYYMMDD HH24MISS') FROM DUAL;
ㄷ. TO_DATE(문자열, 포맷)
-- 포맷 형식의 문자형의 데이터를 날짜형으로 변환해주는 함수이다.
SELECT TO_DATE('20240628', 'YYYYMMDD') FROM DUAL;
(2) NULL 관련 함수
1. NVL(인수1, 인수2)
-- 인수1의 값이 NULL일 경우 인수2를 반환하고 NULL이 아닐 경우 인수1을 반환해주는 함수 -- SQL SERVER의 경우 ISNULL(인수1, 인수2)
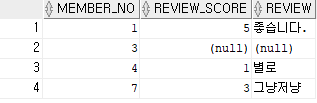
SELECT * FROM TB_SAMPLE7;
SELECT MEMBER_NO
,NVL(REVIEW_SCORE, 0) AS REVIEW_SCORE
FROM TB_SAMPLE7;
2. NULLIF(인수1, 인수2)
-- 인수1과 인수2가 같으면 NULL을 반환하고 같지 않으면 인수1을 반환해주는 함수 -- REVIEW_SCORE(컬럼) 데이터가 0일 경우 NULL을 반환하고, 0이 아닐경우 REVIEW_SCORE 값을 반환
SELECT * FROM TB_SAMPLE7;
SELECT MEMBER_NO
,NULLIF(REVIEW_SCORE, 0) AS REVIEW_SCORE
,REVIEW
FROM TB_SAMPLE7
WHERE PRODUCT_ID = '100001';
3. COALESCE(인수1, 인수2, 인수3 ...)
-- NULL이 아닌 최초의 인수를 반환해주는 함수이다.
SELECT * FROM TB_SAMPLE8;
SELECT NAME
,COALESCE(PHONE, EMAIL, FAX) AS CONTACT
FROM TB_SAMPLE8;
4. NVL2(인수1, 인수2, 인수3)
-- 인수1이 NULL이 아닌 경우 인수2를 반환하고 NULL인 경우 인수3을 반환하는 함수
SELECT * FROM TB_SAMPLE7;
SELECT MEMBER_NO
,NVL2(REVIEW, '리뷰있음', '리뷰없음') AS REVIEW_CHECK
FROM TB_SAMPLE7;
(3) CASE
-- CASE는 함수와 성격이 같기는 하지만 표현 방식이 함수라기보다는 구문에 가깝다. -- 문장으로는 '~이면 ~이고, ~이면 ~이다' 식으로 표현되는 구문 -- 필요에 따라 각 CASE를 여러 개로 늘릴 수도 있다. -- 같은 기능을 하는 함수로는 ORACLE의 DECODE함수가 있다. -- 다음 구문은 모든 같은 결과값을 반환한다. *[]은 옵션
SELECT * FROM TB_SAMPLE9;
-- 아래 SQL 코드는 모두 같은 결과를 나타냅니다.
SELECT SUBWAY_LINE,
CASE WHEN SUBWAY_LINE = 1 THEN 'BLUE'
WHEN SUBWAY_LINE = 2 THEN 'GREEN'
WHEN SUBWAY_LINE = 3 THEN 'ORANGE'
ELSE 'GRAY'
END AS LINE_COLOR
FROM TB_SAMPLE9;
SELECT SUBWAY_LINE,
CASE SUBWAY_LINE
WHEN 1 THEN 'BLUE'
WHEN 2 THEN 'GREEN'
WHEN 3 THEN 'ORANGE'
ELSE 'GRAY'
END AS LINE_COLOR
FROM TB_SAMPLE9;
SELECT SUBWAY_LINE,
DECODE(SUBWAY_LINE, 1, 'BLUE', 2, 'GREEN', 3, 'ORANGE', 'GRAY') AS LINE_COLOR
FROM TB_SAMPLE9;
-- TIP) CASE 문에서 ELSE 뒤의 값이 DEFAULT 값이 되고 별도의 ELSE가 없을 경우 NULL이 DEFAULT가 된다.
연습문제) 다음 SQL의 결과는?
SELECT
CASE WHEN COL1 = 'C' THEN SUBSTR(COL2, 2, 1)
WHEN COL1 = '가' THEN 'C'
WHEN COL1 = '1' THEN '10'
ELSE 'B'
END AS RESULT
FROM TB_SAMPLE10;
ASCII 코드를 인수로 입력했을 때 매핑되는 문자가 무엇인지를 알려주는 함수 SQL SERVER 인경우 CHAR(ASCII 코드)
SELECT CHR(65) FROM DUAL;
2. LOWER(문자열)
문자열을 소문자로 변환해주는 함수이다.
SELECT LOWER('JENNIE') FROM DUAL;
3. UPPER(문자열)
문자열을 대문자로 변환해주는 함수이다.
SELECT UPPER('jennie') FROM DUAL;
4. LTRIM(문자열, [특정문자]) *[]은 옵션임
특정문자를 따로 명시하지 않으면 문자열의 왼쪽 공백을 제거 명시해주었을 경우 문자열을 왼쪽부터 한 글자씩 특정문자와 비교하여 특정 문자에 포함되어 있으면 제거, 포함되지 않았으면 멈춘다. SQL SERVER의 경우 공백 제거만 가능하다.
SELECT LTRIM(' JENNIE') FROM DUAL;
SELECT LTRIM('블랙핑크', '블랙') FROM DUAL;
5. RTRIM(문자열, [특정문자]) *[]은 옵션
특정문자를 바로 명시해주지 않으면 문자열의 오른쪽 공백을 제거 명시해주었을 경우 문자열을 오른쪽부터 한 글자씩 특정문자와 비교하여 특정 문자에 포함되어 있으면 제거하고 포함되지 않으면 멈춘다. SQL SERVER의 경우 공백 제거만 가능하다.
SELECT RTRIM('JENNIE ') FROM DUAL;
SELECT RTRIM('블랙핑크', '핑크') FROM DUAL;
6. TRIM([위치] [특정문자] [FROM] 문자열) *[]은 옵션
-- 옵션이 하나도 없을 경우 문자열의 왼쪽과 오른쪽 공백을 제거하고 -- 그렇지 않을 경우 문자열을 위치(LEANDING OR TRAILING OR BOTH)로 지정된 곳 부터 -- 한 글자씩 특정문자와 비교하여 같으면 제거, 같지않으면 멈춘다. -- LTRIM, RTRIM과는 달리 특정 문자는 한 글자만 지정할 수 있다. -- SQL SERVER의 경우 공백 제거만 가능하다.
SELECT TRIM(' JENNIE ') FROM DUAL;
SELECT TRIM(LEADING '블' FROM '블랙핑크') FROM DUAL;
SELECT TRIM(TRAILING '크' FROM '블랙핑크') FROM DUAL;
7. SUBSTR(문자열, 시작점[길이]) *[]은 옵션
-- 문자열의 원하는 부분만 잘라서 반환해주는 함수 -- 길이를 명시하지 않았을 경우 문자열의 시작점부터 문자열의 끝까지 반환된다. -- SQL SERVER의 경우 SUBSTRING(문자열)
SELECT SUBSTR('블랙핑크제니', 3, 2) FROM DUAL;
SELECT SUBSTR('블랙핑크제니', 3, 4) FROM DUAL;
8. LENGTH(문자열)
-- 문자열의 길이를 반환해주는 함수 -- SQL SERVER의 겨웅 LEN(문자열)
SELECT LENGTH('JENNIE') FROM DUAL;
SELECT LENGTH('블랙핑크') FROM DUAL;
9. REPLACE(문자열, 변경 전 문자열, [변경 후 문자열]) *[]은 옵션
-- 문자열에서 변경 전 문자열을 찾아 변경 후 문자열로 바꿔주는 함수이다. -- 변경 후 문자열을 명시해주지 않으면 문자열에서 변경 전 문자열을 제거한다.
SELECT REPLACE('블랙핑크제니', '제니', '지수') FROM DUAL;
SELECT REPLACE('블랙핑크제니', '블랙') FROM DUAL;
10. LPAD(문자열, 길이, 문자)
-- 문자열이 설정한 길이가 될 때까지 왼쪽을 특정 문자로 채우는 함수
SELECT LPAD('JENNE', 10, 'V') FROM DUAL;
(2) 숫자함수
1. ABS(수)
-- 수의 절댓값을 반환해주는 함수
SELECT ABS(-1) FROM DUAL;
SELECT ABS(2) FROM DUAL;
컬럼을 따로 명시하지 않고 *(asterisk)를 쓰면 전체 컬럼이 조회되며 조회되는 컬럼의 순서는 테이블의 컬럼 순서와 동일, 별도의 WHERE 절이 없으면 테이블의 전체 Row가 조회됨!
SELECT * FROM 테이블;
테이블이나 컬럼명에 별도의 별칭(Alias)를 붙여줄 수 있음
여러개의 테이블을 조인하거나 서브쿼리가 있을 때 컬럼명 앞에 테이블명을 같이 명시해야 하는 경우
예제
다음 중 문법 에러가 발생하는 SQL은 어느 것일까?
1. select d.dept_no from departments d;
2. select departments.dept_no from departments t where dept_no = 'd009';
3. select departments.dept_no from departments where dept_no = 'd009';
4. select dept_no from departments t where t.dept_no = 'd009';
정답 ) 2
풀이) 테이블 명에 Alias를 설정했을 경우 컬럼명에 테이블 명 대신 Alias를 이용해야 한다.
select t.dept_no from departments t where dept_no = 'd009';
산술연산자
수학에서 사용하는 사칙연산의 기능을 가진 연산자
NUMBER DATE 유형의 데이터와 같이 사용할 수 있다.
( ) : 괄호로 우선순위를 조정할 수 있음
: 곱하기
/ : 나누기
: 더하기
: 빼기
select 10+5, 10-5, 10*5, 10/5 from dual;
select * from sample;
select col1 + col2 AS A,
col1 - col2 AS B,
col1 * col2 AS C,
col1 / col2 AS D
from sample;
select col1+col2*col1 AS R1,
(col1+col2)*col1 AS R2
from sample;
예제
다음 SQL의 결과는 무엇인가?
select col1 + col2 AS RESULT from sample2;
[SAMPLE2 테이블]
정답)
해설) 다른 컬럼끼리 연산(가로연산)에서 NULL이 포함되어 있으면 결과값은 Null이 된다.
합성 연산자
문자와 문자를 연결할 때 사용하는 연산자
-- Oracle
SELECT 'S'||'Q'||'L'||'개'||'발'||'자' AS SQLD FROM DUAL;
-- MySQL
SELECT CONCAT('S', 'Q', 'L', '개', '발', '자') AS SQLD FROM DUAL;
select * from sample3;
-- Oracle
select col1 || ' ' || 'SQLD' || ' ' || col2 AS RESULT from sample3;
-- MySQL
select concat(col1, ' ', 'SQLD', ' ', col2) AS RESULT from sample3;